本文共 3188 字,大约阅读时间需要 10 分钟。
搞了一个下午,在Linux和Windows下都成功了,步骤相差不大。一些小问题,google一下就能解决。但还是推荐在linux下搭建,很容易切稳定。
1.必要条件
Cygwin :我的版本是目前最新的2.774
java JDK
hadoop 0.20.2 迅雷连接(有可能已经失效):thunder://QUFodHRwOi8vZGwuY3IxNzMuY29tLy9zb2Z0My9oYWRvb3AuemlwWlo=
eclipse
2. java安装
具体参考百度。。。。。
3.Cygwin的安装
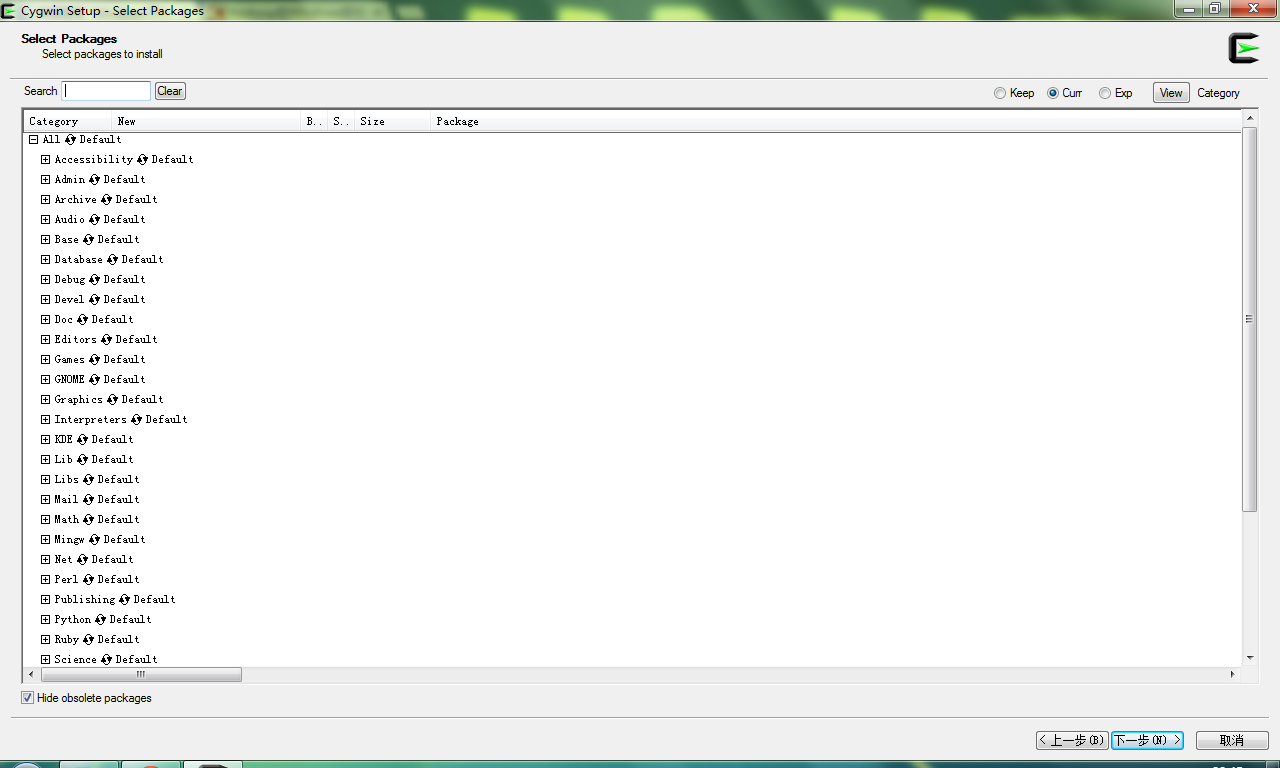
可以按照默认的提示安装到自己需要存放的位置,但是在安装时需要注意下面几点:
- Net 下的:openssh,openssl

- Base 下的:sed (若需要Eclipse,必须sed)
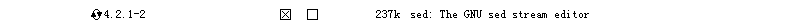
- Devel 下的:subversion(建议安装)
不同的版本可能有所不同,但是基本操作没有变化。。。。
CygWin的bin目录以及usr/sbin 追加到系统环境变量PATH中。
4.启动SSH服务
以管理员权限运行Cygwin,并输入
SSH-HOST-CONFIG
接下来,系统会提示以下信息
should privilege separation be used ? 回答:noif sshd should be installed as service? 回答:yesthe value of CYGWIN environment variable 输入: ntsec
成功的话,会有下面的提示
Host configuration finished. Have fun!
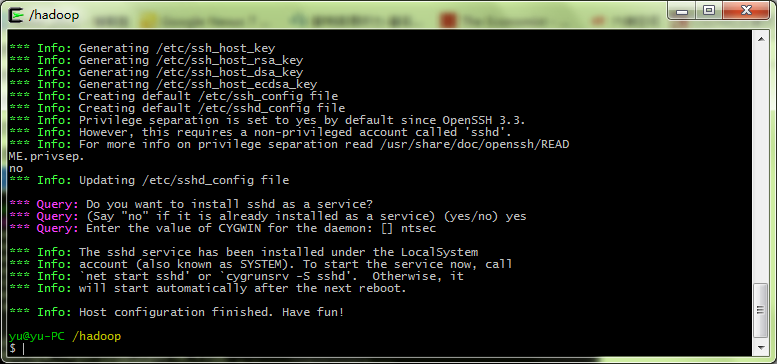
不要高兴太早,我们还需要在Windows服务中,开启Cygwin服务。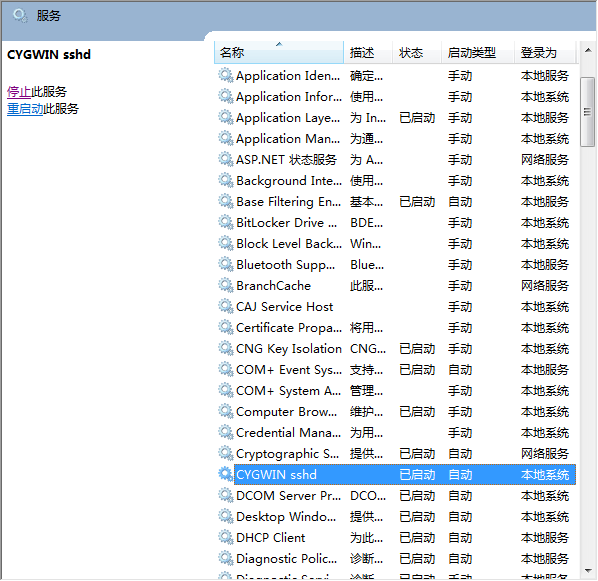
还有活要干。。。
在Cygwin下操作:
- 输入ssh-keygen,回车直到完成输出
- 进入~/.ssh,cd ~/.ssh
- 复制,cp id_rsd.pub anthorized_keys
- 退出,exit
如果没有任何问题的话,应该是完成了。
输入ssh localhost开启SSH服务。(PS:这里我一直都是错误的,不知道为啥我重启下了电脑,好了)
5.hadoop安装
下载hadoop,解压缩到Cygwin下,修改名称为hadoop,方便使用。这里只部署在一个机器上。
需要我们首先修改一些Hadoop的配置信息(这里的端口9000和9001确保没有被占用,也可改变为其他):
- hadoop-env.sh
- core-site.xml
- hdfs-site.xml
- mapred-site.xml
//打开hadoop/conf/hadoop-env.sh文件export JAVA_HOME=/usr/lib/jvm/java
//打开conf/core-site.xml文件fs.default.name hdfs://localhost:9000
//打开conf/mapred-site.xml文件mapred.job.tracker localhost:9001
//打开conf/hdfs-site.xml文件
dfs.name.dir /usr/local/hadoop/datalog1,/usr/local/hadoop/datalog2 dfs.data.dir /usr/local/hadoop/data1,/usr/local/hadoop/data2 dfs.replication 1
可以启动hadoop了,激动~~
1.创建Logs日志目录
mkdir logs
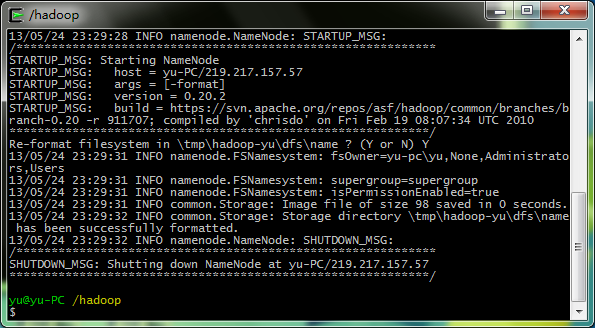
2.格式化namenode,创建HDFS(这要进入hadoop文件夹内操作)
bin/hadoop namenode -format
3.启动hadoop
bin/start-all.sh
4.执行JPS

完成启动~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
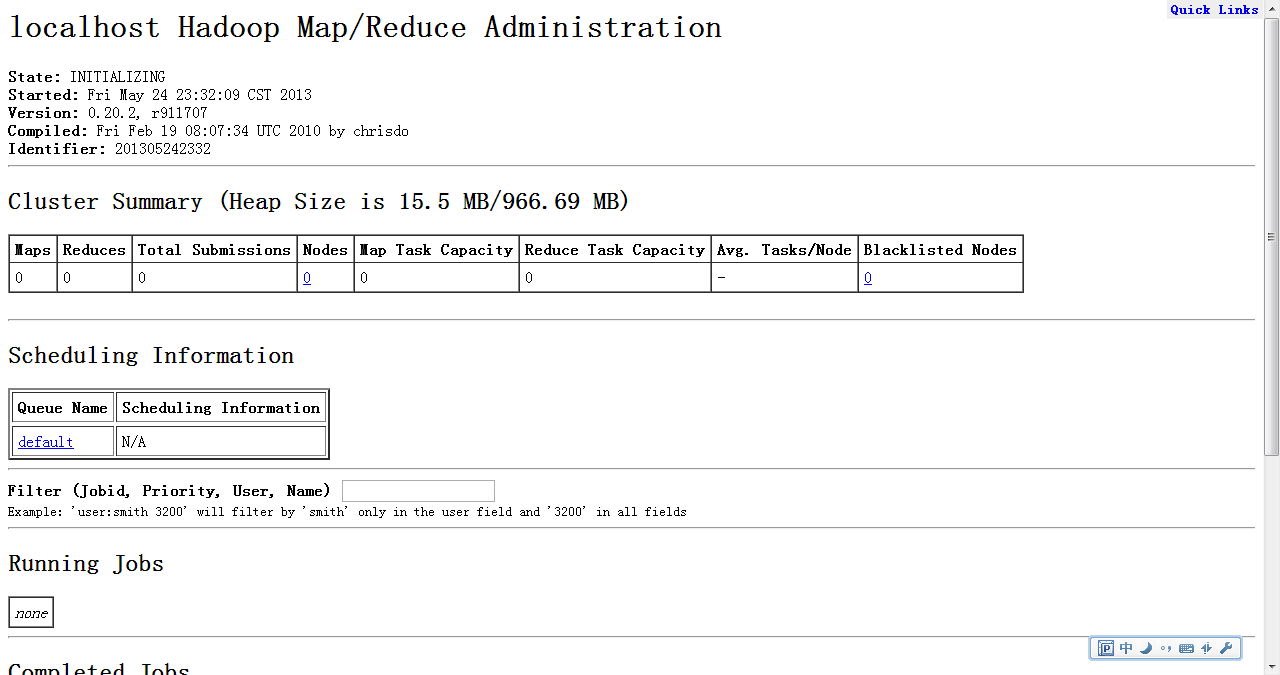
输入网址:
6.配置eclipse
Hadoop自带eclipse插件,在hadoop\contrib\eclipse-plugin中。
具体配置步骤如下:
hadoop-0.20.2-eclipse-plugin.jar放入eclipse的插件文件夹中,开启eclipse。
window->Preference->Hadoop Map/Reduce,输入hadoop文件夹位置。
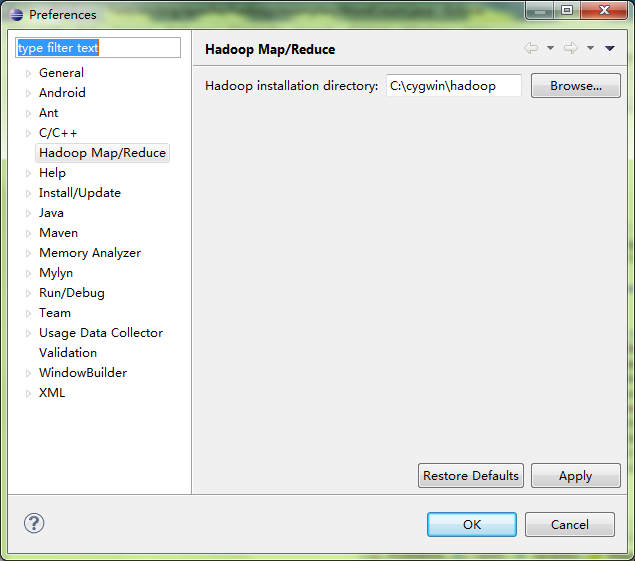
window->Show View,选择Map/Reduce Locations。
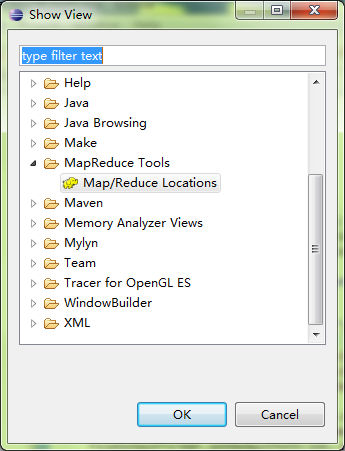
点击屏幕右下方新建一个Location.
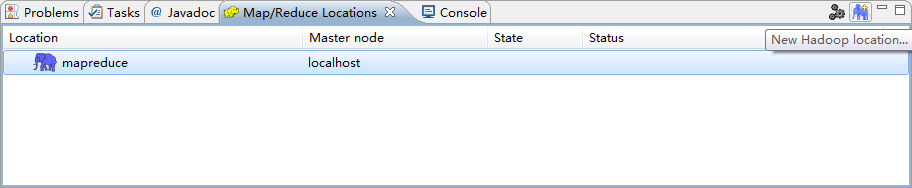
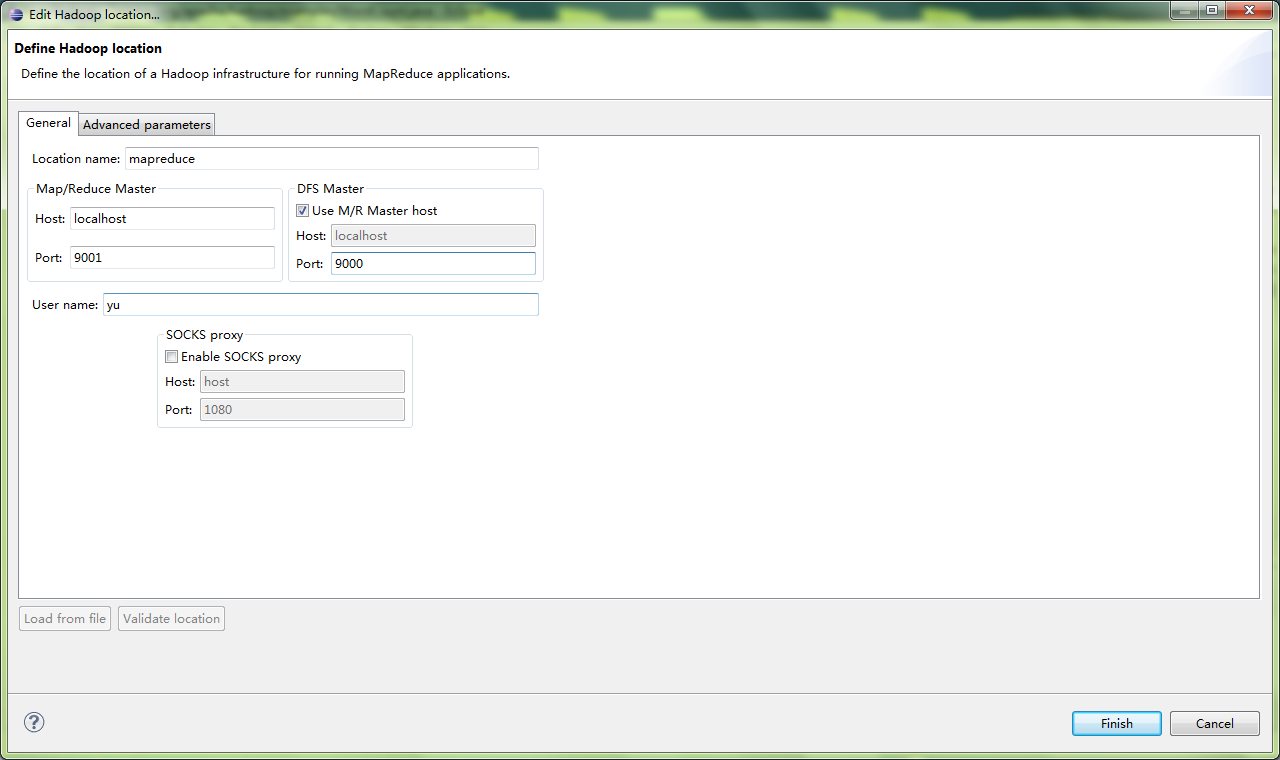
编辑Location.(注意MAP/REDUCE和DFS的Port分别对应mapred-site.xml和core-site.xml),高级的我设置了Hadoop.tmp.dir
这时,打开Project Explore,刷新。
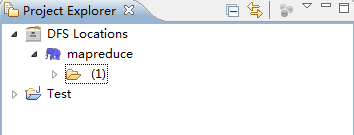
接下来,你可以new一个MapReduce程序了,找到hadoop的例子试试去吧。
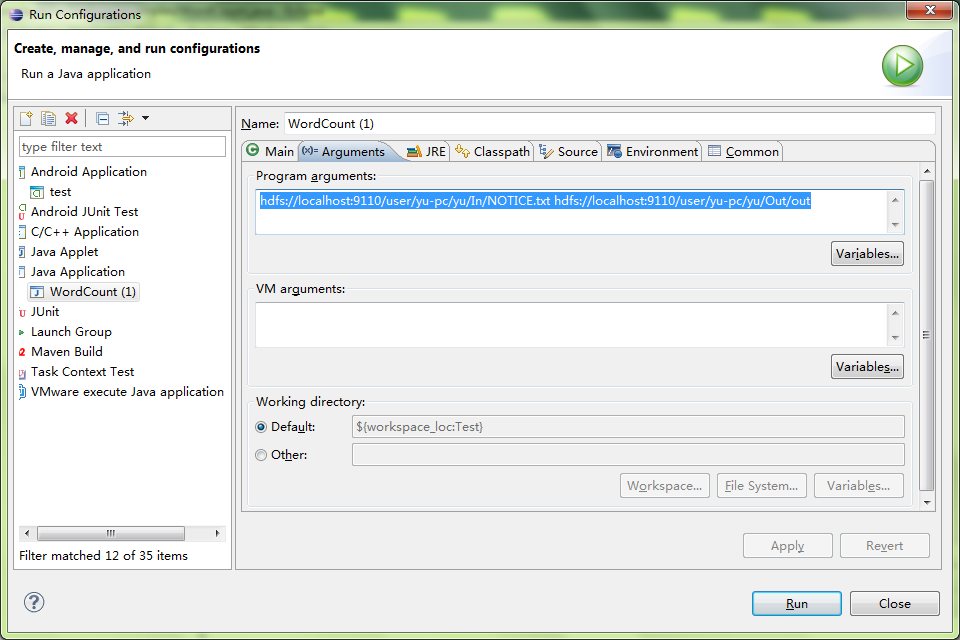
对了,编译这里要配置一下。
选择Run Configurations->Java Application->Arguments,这里要填入为两个文件,分别为输入文件和输出文件。
本文转自cococo点点博客园博客,原文链接:http://www.cnblogs.com/coder2012/archive/2013/05/25/3096631.html,如需转载请自行联系原作者